컴퓨터 하드웨어 - 3. CPU (2편)
1. 명령어 셋 아키텍처
앞선 포스트에서는 CPU가 기본적으로 어떻게 동작하는지를 큰 그림에서 알아보았습니다. 위 내용은 비단 PC CPU 뿐만 아니라 여러분들이 일반적으로 접할 수 있는 거의 모든 CPU가 작동하는 방식이라고 볼 수 있습니다.
그러면 이런 일반적인 동작 방식을 구체적으로 어떻게 설계할지는 또 다른 문제입니다. 가령 명령어는 어떤 걸 준비할지, 레지스터는 어떤 종류를 몇개 준비할지, 메모리 접근은 어떤 방식으로 수행할지 등과 같은 문제가 있다는 것입니다.
따라서 명령어의 종류, 레지스터의 종류, 메모리 접근 방식 등을 모아서 하나로 정의한 아키텍처가 필요하게 됩니다. 이 아키텍처를 명령어 셋 아키텍처 (Instruction Set Architecture, ISA) 라고 부릅니다.
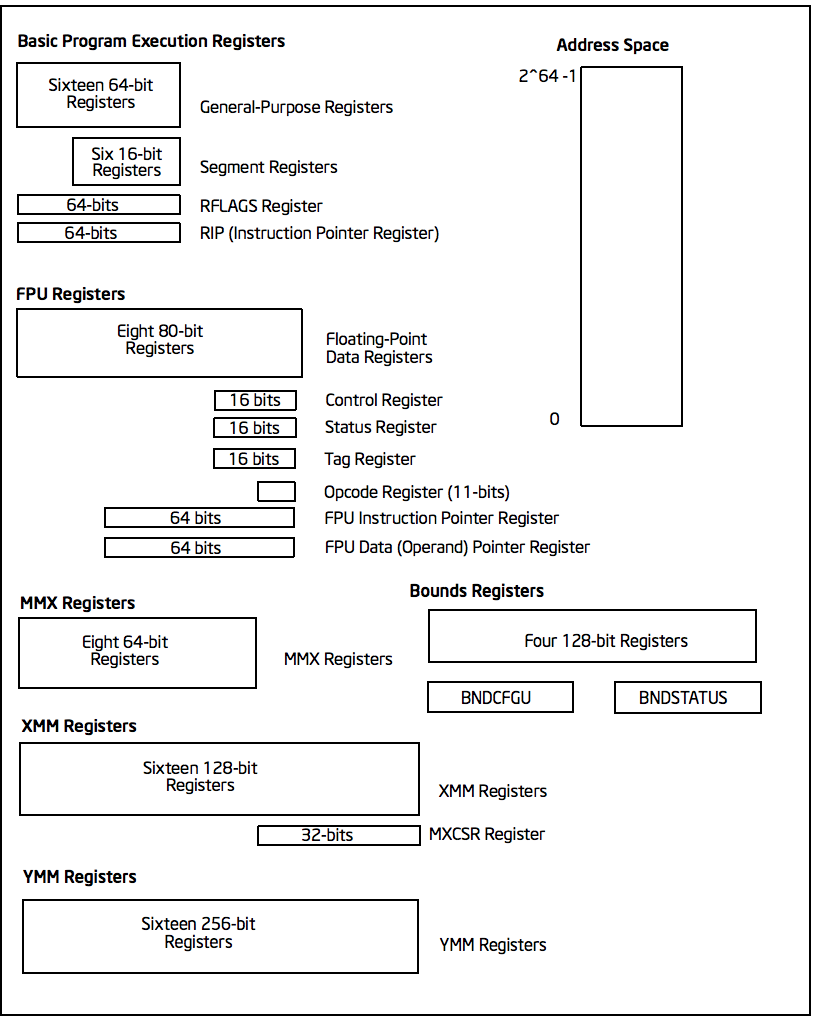 PC CPU의 ISA인 x86-64 ISA
PC CPU의 ISA인 x86-64 ISA
ISA는 명령어의 종류와 레지스터의 종류를 직접적으로 결정하기 때문에 컴파일러와도 아주 깊은 관련이 있습니다. 앞서 컴파일러는 코드를 기계어로 번역하는 작업을 수행한다고 했는데, 코드가 어떤 ISA에서 돌아가는지를 알아야 그에 맞는 기계어를 만들 수 있을 것입니다. 따라서 ISA가 달라지면 이전 ISA로 컴파일된 프로그램은 완전히 무용지물이 되고 달라진 ISA에 맞는 컴파일러로 다시 코드를 컴파일해야 합니다.
1.1. ISA의 종류
이 글에서 주로 다루는 PC CPU의 ISA는 정식 명칭은 AMD64 또는 x86-64 라고 부르며, 줄여서 x64라고도 흔히 부릅니다. 70년대부터 관습적으로 쓰여오던 명칭인 x86도 흔히 쓰이는데 이는 보통 32비트 아키텍처를 의미합니다. PC CPU가 사용하는 ISA의 명칭에 관해서는 내용이 길어서 별도 포스트에서 다루도록 하겠습니다.
CPU가 PC CPU만 있는 것은 아니니 ISA 또한 그러한데, 컴퓨터에 좀 더 관심이 있으신 분들은 ARM도 많이 들어보셨을 것 같습니다. ARM은 회사 이름으로서 이 회사에서 만드는 ISA와 이 ISA를 통해 만들어진 CPU까지 의미하기도 합니다. 보통 ARM 아키텍처 혹은 ARM CPU 와 같이 부르게 됩니다.
ARM은 자사에서도 밀고 있는 특징으로 저전력이 있습니다. 지금에서야 일부 고성능 서버에도 ARM CPU가 쓰이므로 ARM CPU가 무조건 저전력이다라고 하는 건 어폐가 있지만, 전력이 제한된 상황에서는 확실히 좋은 성능을 보여준다는 이점이 있습니다. 그렇기 때문에 스마트폰과 태블릿 PC는 사실상 전부 ARM CPU를 사용하고 있습니다.
ARM은 사업구조가 다소 독특한 편으로 자신들이 만든 레퍼런스 아키텍처를 그대로 제공하기도 하고, 이를 기반으로 아예 커스텀이 가능한 라이센스 또한 제공합니다. 대표적으로 Apple이 ARM의 아키텍처를 사용하면서 이를 자사 제품 목적에 맞게 완전 커스텀한 아키텍처를 만들고 있습니다. 이외에도 퀄컴의 스냅드래곤 (Snapdragon), 삼성의 엑시노스 (Exynos) 등이 ARM의 아키텍처를 커스텀하여 만드는 대표적인 제품들입니다.
 Apple이 자체 제작하는 ARM 아키텍처 기반 CPU인 Apple M1
Apple이 자체 제작하는 ARM 아키텍처 기반 CPU인 Apple M1
ARM 말고도 2010년대 이후로 각광을 받고 있는 ISA 중에는 RISC-V 라는 ISA도 있습니다. RISC-V의 가장 큰 특징이라면 ISA 자체가 오픈 소스라는 것입니다. 기존 x86, x64, ARM 아키텍처들은 모두 회사에 종속된 아키텍처이고 다른 회사가 사용하려면 라이센스 비용이 발생했는데1, RISC-V는 그런 제약이 없어서 어느 회사든 자유롭게 제품을 개발할 수 있어 임베디드 업계를 중심으로 조금씩 점유율을 늘려가고 있습니다.
 ARM과 RISC-V
ARM과 RISC-V
이외에도 비교적 특수한 환경에서 사용하는 ISA들도 다양하게 있는데요, IBM의 POWER, 컴퓨터 아키텍처 전공 수업에서 자주 다루는 MIPS 등이 나름 유명하다고 할 수 있습니다.
1.2. CISC와 RISC
지금까지 ISA를 얘기하면서 저는 CISC와 RISC라는 단어를 의도적으로 배제했는데, 전통적으로 ISA를 얘기할 때는 이 둘을 얘기하는 경우가 많습니다.
CISC와 RISC는 각각 Complex Instruction Set Computer와 Reduced ISC를 의미하는 것으로 ISA의 특징을 구분하기 위해 만들어진 용어입니다. 2
보통 x86과 x64 계열은 CISC, ARM과 RISC-V (이름 그 자체이기도 하지만..)는 RISC로 분류하는데, 이는 x86 계열 아키텍처가 복잡한 구조의 명령어를 가지고 있기 때문에 붙여진 이름입니다. 명령어 구조가 복잡하다는 것은 다양한 의미가 있겠지만 보통은 서로 다른 명령어의 길이가 다르다는 것을 의미합니다. 반대로 RISC는 대부분 명령어가 같은 길이를 갖게끔 설계합니다. 아래 그림은 앞서 예시로 보인 똑같은 1 + 2 = 3 프로그램을 x86 (CISC)과 RISC-V (RISC) 용으로 컴파일 했을 때 나오는 기계어를 비교한 것입니다.
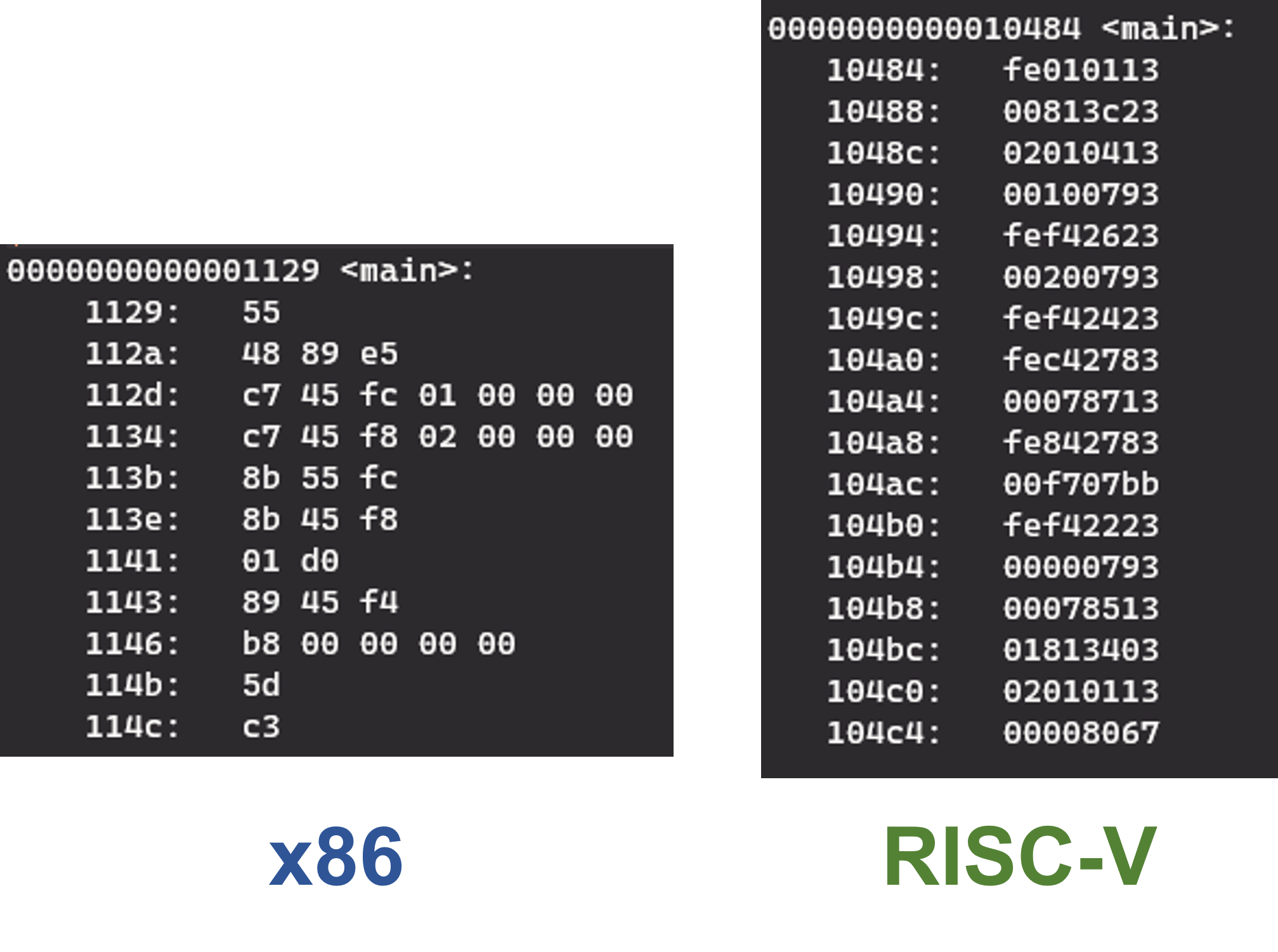 CISC와 RISC 기계어 길이 비교 (x86과 RISC-V)
CISC와 RISC 기계어 길이 비교 (x86과 RISC-V)
그래서 RISC가 나왔던 배경은 CISC 명령어가 너무 복잡하니 하드웨어를 구현하기가 복잡하고 하드웨어가 복잡하다는 것은 곧 전력 소모가 늘어난다는 것이라 이런 단점을 보완하기 위함이라고 할 수 있습니다. 이것 말고도 RISC가 등장한 배경은 다양할 수 있지만 핵심은 명령어 구조를 간소화 하자가 목적이라고 할 수 있습니다. 그렇지만 명령어 구조가 간소화되면서 CISC에서는 명령어 한두개로 할 수 있던 복잡한 작업을 더 많은 명령어로 수행해야 하는 단점이 생기기도 합니다. 공학이란 게 언제나 그렇지만 얻는 게 있으면 잃는 게 있는 법 (trade-off) 입니다. 이는 위의 비교 그림으로도 쉽게 알 수 있습니다.
하지만 흔히들 얘기하는 CISC와 RISC의 장단점도 현재에 와서는 상당 부분 무의미해졌는데, 단적으로 x64 계열 CPU들은 실제 구현 단에서 RISC처럼 동작하기도 하고, ARM 계열 CPU들도 복잡한 연산을 처리하기 위해 명령어가 점점 복잡해지고 있기 때문입니다. 따라서 이런 용어가 있다는 것만 알아두시고, 각 ISA 별 특징을 보는 게 맞지 이 분류에는 너무 집착하지 않는 것을 권장합니다.3
2. 마이크로아키텍처
PC CPU의 마이크로아키텍처를 매우 상세히 다룬 국내의 컨텐츠가 있습니다.
닥터몰라님의 CPU WARS를 참조하시면 PC CPU의 마이크로아키텍처의 변천과 더불어
마이크로아키텍처 각각의 구체적인 구현 방식을 확인할 수 있습니다.
보러 가기
앞서 ISA가 CPU의 아키텍처라고 약간은 뭉뚱그려서 설명을 했습니다. 하지만 CPU 아키텍처를 얘기할 때는 ISA 말고 한가지를 더 얘기하게 됩니다. 일단 ISA를 다시 한 문장으로 정리하면 CPU가 이런 식으로 동작해야 한다를 정의한 아키텍처입니다. 이는 ISA가 구현상의 문제를 전혀 고려하지 않았다고는 할 수 없지만 구현보다는 이론적인 측면이 강조된 것임을 의미합니다.
그래서 이 ISA를 실제로 구현하기 위해선 어떤 하드웨어들을 어떻게 조합할지를 고려해야 합니다. 이런 구현상의 문제를 고려하여 ISA를 실제 하드웨어로 구현한 아키텍처를 마이크로아키텍처 (Microarchitecture) 라고 부릅니다. 굳이 비유하면 ISA는 건물의 설계도랑 비슷하고, 마이크로아키텍처는 실제 건설된 건물이랑 비슷하다고 보시면 됩니다.
따라서 같은 ISA 안에서도 수많은 마이크로아키텍처가 존재합니다. 또한 CPU를 이루는 하드웨어라면 결국 반도체로 만들어지기 때문에 반도체 공정이 발전하면 마이크로아키텍처도 발전하고 그에 따라 CPU 성능도 올라가게 됩니다. 즉 최신 CPU는 구형 CPU와 (거의) 같은 명령어를 훨씬 빠른 속도로 실행할 수 있는 것입니다. 4
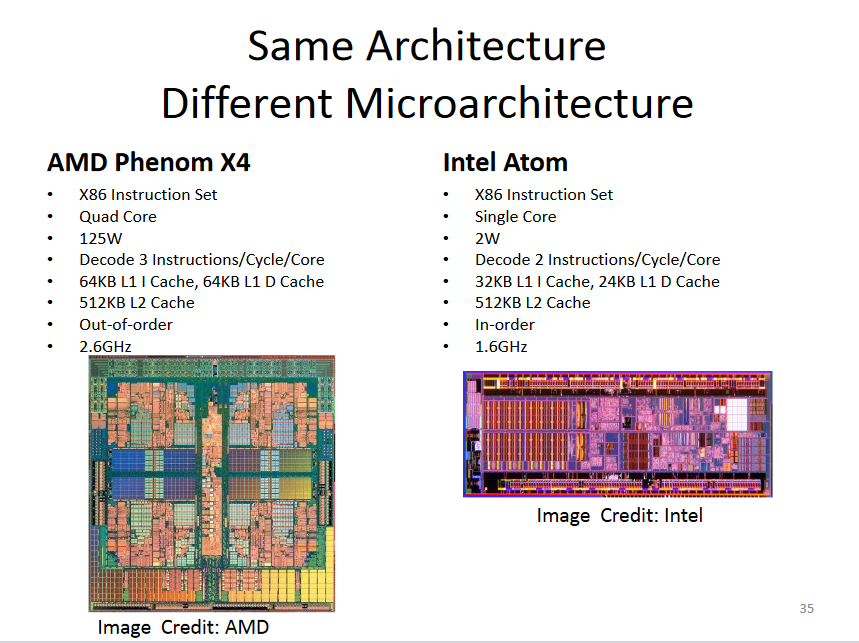 같은 ISA를 구현한 서로 다른 마이크로아키텍처
같은 ISA를 구현한 서로 다른 마이크로아키텍처
2.1. CPU 코어
지금까지 제가 사용한 CPU라는 단어는 마이크로아키텍처 입장에서 보면 어느 정도 추상화를 거친 의미라고 할 수 있습니다. 이 말은 그동안 CPU라고 하면 ISA에 의해 정의된 명령어를 실행하는 어떤 것 정도의 의미만을 가졌다는 것입니다.
마이크로아키텍처는 이 명령어를 구체적으로 실행할 하나의 단위를 코어 (Core) 라는 이름으로 구현합니다. 즉 CPU라는 큰(?) 부품 안에 명령어 계산을 위한 코어라는 서브 시스템이 있는 개념으로 보시면 됩니다. 그렇다는 것은 CPU 안에는 코어가 아닌 것도 있다는 얘긴데 이는 주로 언코어 (Uncore) 라는 이름으로 불립니다. 언코어 관련해서는 코어 설명이 끝나면 설명하도록 하겠습니다.
 AMD ZEN3 CPU 내부에서 코어의 모습 (빨간색 상자). 이런 그림을 Die shot이라 부릅니다
AMD ZEN3 CPU 내부에서 코어의 모습 (빨간색 상자). 이런 그림을 Die shot이라 부릅니다
그러면 코어가 하는 일은 무엇일까요? 의외로 코어가 하는 일은 대부분 이전 포스트에서 설명이 되었습니다. 바로 코어는 CPU 명령어 사이클을 직접 실행하는 주체입니다. 그래서 여기서는 이 명령어 사이클 각각을 코어의 어떤 부분이 담당하는지 간단하게나마 뜯어보고자 합니다. 5 (refresh를 위해 그림도 다시 가져오겠습니다)
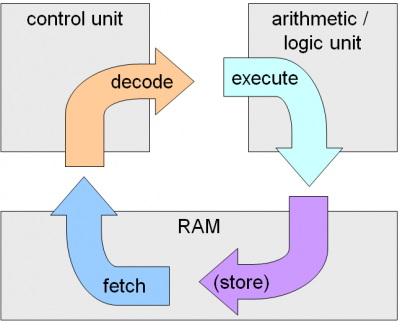 다시 돌아온 명령어 사이클
다시 돌아온 명령어 사이클
2.2. CPU 코어 - 프론트엔드 (Frotend)
컴퓨터 업계에서는 프론트엔드 (Frontend)와 백엔드 (Backend) 라는 용어를 다양한 맥락에서 사용합니다. 아마 가장 많이 들어본 것은 웹 개발의 그것일 것입니다. 이들 단어를 직역하면 앞단과 뒷단 정도의 의미가 될 텐데, 웹에서는 보통 사용자와 직접 상호작용이 벌어지는 곳을 프론트엔드라 부르고, 사용자가 상호작용을 통해 내린 명령 (API)을 내부적으로 처리하는 곳을 백엔드라고 부릅니다.
CPU 코어에서 말하는 프론트엔드와 백엔드 또한 이런 느낌에서 크게 다르지는 않습니다. 다만 여기는 상호작용의 경계면이 CPU 내외부일 뿐입니다. CPU 코어의 프론트엔드는 외부에서 명령어를 처리하도록 명령을 받으면 명령어를 불러와서 (Fetch) 해석 (Decode)하는 역할을 수행합니다.
명령어를 불러오는 명령어가 메모리에 저장되어 있으니 거기서 불러와야 할 것입니다6. 이 부분은 언코어 파트의 내용도 필요하기 때문에 일단은 이 정도로만 요약하겠습니다. 이후 불러온 명령어를 해석 (Decode)하는 작업을 수행해야 합니다.
그런데 명령어를 해석한다는 것이 무슨 의미일까요? 이제는 하도 우려서 사골이 되지 않았을까 하는(…) x86 아키텍처의 add 명령어 예시를 다시 확인해보겠습니다. 편의상 이미지 전체가 아닌 add 명령어 부분만 가져오겠습니다.
1
1141: 01 d0 add %edx,%eax
메모리 주소 말고 그 뒤에 16진수 부분이 실제 메모리에 저장되는 명령어 형태입니다. 2바이트이므로 비트로 풀어보면 0000_0001_1101_0000이 저장되어 있는 것입니다7 CPU가 메모리로부터 명령어를 받은 상태가 딱 이 상태인데, 그냥 봐서는 이게 add 명령어인지 어떻게 알 수 있을까요?
ISA 파트에서 명령어는 ISA가 사전 정의한 포맷에 의해서 종류가 결정된다고 하였습니다. 그러면 x86 ISA는 add 명령어를 어떻게 정의했는지 확인할 필요가 있겠습니다.
먼저 x86 ISA의 명령어 포맷은 아래와 같습니다.
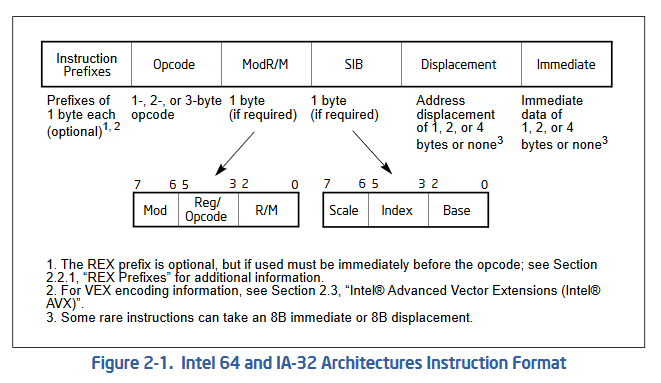 x64 ISA의 명령어 포맷 (인텔 공식 문서)
x64 ISA의 명령어 포맷 (인텔 공식 문서)
포맷이 꽤 복잡합니다. 앞서 x86 ISA는 명령어마다 길이가 다 다르다고 했는데, 그렇기 때문에 모든 명령어가 이 포맷에 있는 모든 영역을 사용하지 않습니다. 결론부터 얘기하면 우리가 살펴볼 add 명령어는 1바이트의 Opcode와 ModR/M 영역만 사용합니다. 따라서 앞선 01 파트가 Opcode 파트이고 뒤에 d0가 ModR/M 파트라고 할 수 있습니다.
즉 명령어를 해석한다는 것은 이 포맷에 맞게 명령어를 해석해서 종류가 무엇이었고 어떤 작업을 해야 하는지를 정하는 것을 의미합니다. 이 부분이 코어의 프론트엔드가 수행하는 핵심 역할이며 이를 수행하는 장치를 디코더 (Decoder)라고 부릅니다. 이 디코더가 코어 하나에 몇개 있는지가 나름 중요한 스펙인데, 그래서 디코더가 N개 있는 경우 N-way 디코더라고 흔히 표현합니다. 이 N개의 디코더는 모두 병렬적으로 작동할 수 있어서 동시에 최대한 많이 작동하는 게 성능에 유리하게 됩니다. 아래는 2023년 인텔의 최신 CPU인 랩터 레이크 (Raptor Lake)에 쓰인 골든 코브 마이크로아키텍처의 예시인데 6-way 디코더를 사용했음을 알 수 있습니다8.
 골든 코드 마이크로아키텍처의 프론트엔드 (출처)
골든 코드 마이크로아키텍처의 프론트엔드 (출처)
코어의 프론트엔드는 이외에도 분기 예측 (Branch Prediction) 이라는 현대 CPU 마이크로아키텍처에서 절대 빼놓을 수 없는 기법 또한 수행합니다. 다만 이를 알려면 아직까지 다룬 내용만으로는 부족하기 때문에 일단은 생략하고 넘어가겠습니다.
2.3. CPU 코어 - 백엔드 (Backend)
코어의 프론트엔드는 명령어를 해석하는 역할을 수행했습니다. 이제 백엔드는 해석된 명령어로 실제 필요한 연산을 수행하는 부분을 의미합니다. 그리고 백엔드 내에서 실제로 연산을 수행하는 장치를 연산 장치 (Execution Unit) 이라고 부릅니다.
CPU가 수행하는 연산의 종류는 CPU 포스트 시작 부분에서 사칙 연산, 논리 연산, shift 연산 등이 있다고 소개하였습니다. 물론 이것만 있는 건 아니고 더 다양한 연산들이 있지만 쉬운 이해를 위해 그 동안 계속 등장해왔던 add 연산으로 예를 들어보겠습니다.
본 시리즈에서 보였던 add는 두개의 정수 (Integer)를 더하는 역할을 수행했습니다. 사실 컴퓨터가 수행하는 대다수의 연산은 정수를 사용하는 연산입니다. C 프로그래밍을 접해보신 분이면 알겠지만 어떤 과학적인 작업을 하는 경우가 아니면 대부분은 int나 unsigned int 같은 자료형을 통해 작업을 수행하는 것을 경험해보셨을 것입니다. 이러한 정수를 처리하는 연산장치를 말 그대로 정수 연산 장치 (Integer Execution Unit) 이라고 부릅니다. 줄여서 간단하게 INT라고도 많이 부릅니다.
정수 연산 장치에는 대표적으로 산술 논리 장치 (Arithmetic Logical Unit, ALU), 쉬프터 (Shifter), 그리고 메모리 주소를 계산하기 위한 주소 생성 장치 (Address Generation Unit)과 실제 메모리 접근을 수행하는 로드-스토어 장치 (Load-store Unit) 같은 것이 있습니다.
 골든 코드 마이크로아키텍처의 정수 연산 유닛. 설명에 나온 것 이외에도 다양한 장치가 있음을 알 수 있습니다. (출처)
골든 코드 마이크로아키텍처의 정수 연산 유닛. 설명에 나온 것 이외에도 다양한 장치가 있음을 알 수 있습니다. (출처)
물론 정수가 아닌 소수점 연산도 컴퓨팅에 필수불가결한 요소이므로 이를 위한 연산 장치도 존재합니다. 컴퓨터는 소수점을 부동 소수점 (Floating Point)9 방식으로 구현합니다. 그래서 보통 소수점 연산 장치를 부동 소수점 장치 (Floating Point Unit, FPU) 라고 부릅니다.
백엔드의 연산 장치 또한 프론트엔드처럼 N개가 존재하여 이 N개가 동시에 작동할 수 있습니다. 다만 보통은 INT 장치와 FPU를 합쳐서 하나의 단위로 보게 됩니다. 즉 한 단위에 FPU가 작동 중이면 INT 장치는 작동할 수 없는 제약이 있습니다. 또한 메모리 관련 장치는 굉장히 많이 사용되기 때문에 INT 장치와 별개의 장치로 할당되는 경우가 일반적입니다.
프론트엔드와 종합해서 정리하면 CPU 성능은 결국 프론트엔드의 모든 디코더와 백엔드의 모든 연산 장치가 동시에 사용되었을 때 최대의 성능을 보여줄 것입니다. 하나라도 놀면 거기서 병목 (Bottleneck)이 발생하게 되는 것이죠. 그래서 프론트엔드를 무작정 늘리는 것도, 백엔드를 무작정 늘리는 것도 해답은 아니며 둘 사이의 절묘한 지점을 찾는 것이 마이크로아키텍처 설계의 꽃이라 할 수 있겠습니다.
2.4. 클럭 속도
CPU의 성능은 앞서 언급한 프론트엔드와 백엔드의 자원들을 얼마나 잘 활용하는지에 달렸습니다. 그러나 이는 자원 활용의 효율성의 관점에서 봤을 때 그런 것이고, 이들이 물리적으로 동작하는 속도 그 자체도 성능에 영향을 미칠 것입니다.
관련된 이야기를 하기 위해 잠깐 이야기의 흐름을 바꿔보겠습니다. CPU 또한 수많은 트랜지스터가 모여 만들어진 전자회로임은 모두 잘 아실 것이라 생각합니다. 이 전자회로는 결국 0과 1의 흐름을 제어하는 것인데, 전자회로는 0과 1의 구분을 전압 (Voltage)을 통해 수행합니다. 그리고 많은 디테일이 생략된 설명이긴 하나, 어쨌든 전자회로는 이 0과 1의 전환이 얼마나 빨리 이루어지는지에 따라 작동 성능이 어느 정도 결정된다고 할 수 있습니다.
전자회로는 상태 전환을 위해 주기적으로 0과 1이 바뀌는 신호를 사용하는 것이 일반적인데요, 이 주기적으로 바뀌는 신호를 클럭 (Clock)이라고 부릅니다. 그리고 주기적으로 0과 1이 바뀌다 보니 이 바뀌는 주기를 클럭 속도 (Clock Speed)라 하여 헤르츠 (Hz) 단위로 표기합니다.
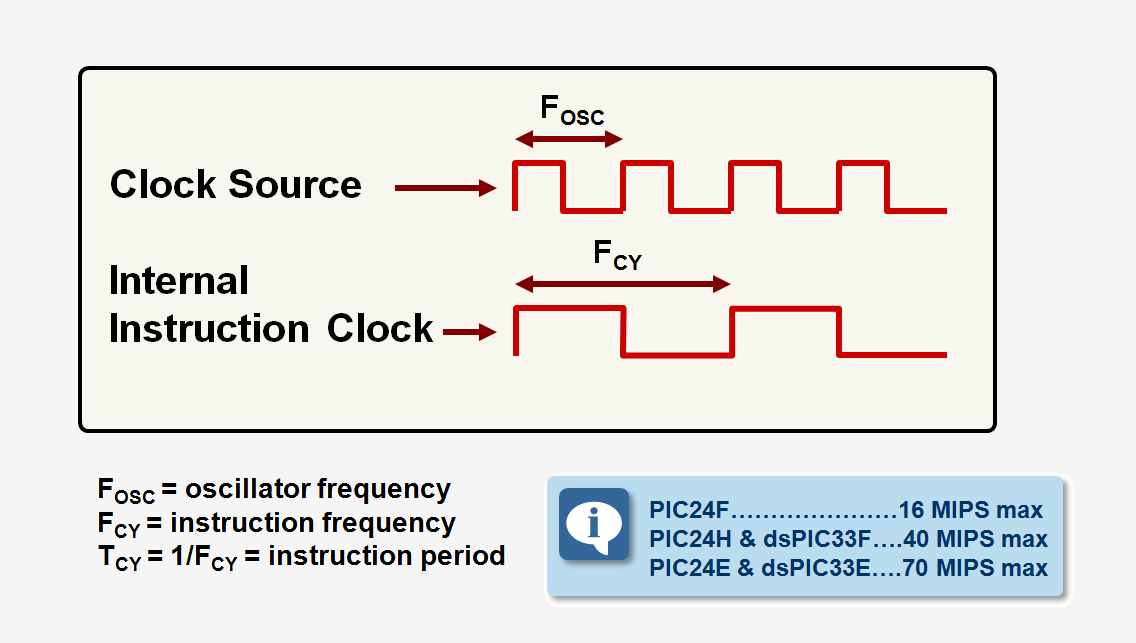 클럭 신호의 모습
클럭 신호의 모습
다시 CPU 얘기로 돌아와서 최신 CPU들은 4-5GHz (Giga Hz, 10억 Hz) 정도의 클럭 속도를 가지고 있습니다. 즉 프론트엔드와 백엔드의 각 요소들이 이 속도로 공급되는 클럭에 따라 작동을 한다고 보시면 됩니다. 다만 이 글에서는 자세히 다루지 않았지만 파이프라인 (Pipeline) 기법 때문에 명령어가 초당 4-50억개씩 처리되는 식은 아닙니다.
 최신 AMD CPU들의 클럭 속도. 인텔도 엇비슷한 수준입니다
최신 AMD CPU들의 클럭 속도. 인텔도 엇비슷한 수준입니다
마지막으로 CPU 스펙을 표기할 때는 예나 지금이나 대표적으로 이 클럭 속도를 표시합니다. 명확히 숫자 하나로 표기되는 만큼 컴퓨터에 익숙하지 않은 소비자들 대상으로 어필하기 가장 좋은 스펙 요소이기 때문입니다. 이 점에 착안해서 2000년대 초반 인텔은 클럭 속도만 높으면 장땡이지 라는 마인드로 아키텍처 개발을 했다가 실성능이 너무 안좋아서 망한 경우도 있을 정도입니다. 그래서 CPU 성능을 좀 더 정확히 알고 싶으면 클럭 속도만 확인하는 건 의미가 없고, 본인이 사용할 용도에서 어느 정도의 성능을 보이는지 따로 벤치마크를 찾아보는 것이 바람직합니다.
2.5 멀티 코어 프로세서
전통적으로 CPU에는 코어가 하나만 있었습니다. CPU 제조사들은 2000년대 초까지는 하나의 코어가 작동하는 속도 (클럭, Clock)를 계속해서 끌어올리는 방식으로 CPU 성능을 올리고자 하였습니다. 하지만 이내 곧 일정 수준 이상으로 클럭을 올리는 것은 물리적으로 어렵다는 것을 깨닫고 CPU 성능 향상을 위해 CPU 하나에 코어를 여러개 두는 방식을 고려하게 됩니다. 이렇게 하여 단일 CPU에 여러 코어가 있는 멀티 코어 프로세서 (Multi Core Processor)가 등장하게 됩니다.
멀티 코어 프로세서가 왜 CPU 성능에 도움이 되는지를 정리하면, 먼저 코어 하나가 하는 역할이 바로 명령어 사이클을 수행하는 것이라고 말씀드렸습니다. 즉 코어 하나는 쉽게 프로그램 하나를 실행하는 것이라 보시면 됩니다. 여기서 코어가 여러개 존재하게 되면 동시에 병렬적으로 서로 다른 프로그램을 실행할 수 있게 됩니다. 이론적으로는 코어가 두개라면 서로 다른 두개의 프로그램을 기존 단일 코어만 있을 때보다 두배 더 빨리 실행할 수 있는 것입니다10.
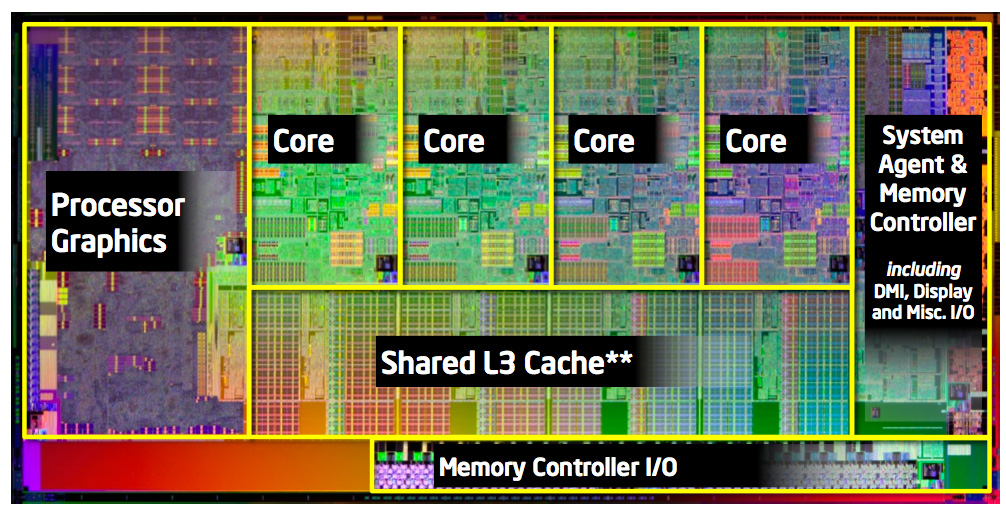 코어가 4개 있는 CPU의 die shot 예시
코어가 4개 있는 CPU의 die shot 예시
멀티 코어 프로세서가 PC에 본격적으로 데뷔한 것은 2005년입니다. 거의 동시기에 인텔과 AMD가 코어가 두개 있는 듀얼 코어 (Dual Core) CPU를 처음 발표하면서 본격적으로 멀티 코어의 시대를 열게 되었습니다. 하지만 멀티 코어를 제대로 사용하기 위해선 운영체제도 그에 맞는 설계가 필요하고, 프로그램들도 멀티 코어를 지원하게 개발이 되어야 하고, 무엇보다 당시에는 개인용 컴퓨터에 멀티 코어가 체감이 될 만한 상황이 많이 없었습니다. 그래서 2010년대 이전까지 최고급 라인업 정도만 쿼드 코어 (Quad Core, 코어 4개)였고 일반적으로 많이 접근하는 라인업은 듀얼 코어에서 계속 머물렀습니다.
그런데 2010년대에 접어들면서 AMD가 끝도 없는 부진을 거듭하자 인텔은 최고 소비자용 라인업을 계속 쿼드 코어로 동결시키며 한동안 코어 수 발전에 정체기가 찾아오게 됩니다. 인텔이 처음 쿼드 코어 CPU를 발표한 것이 2007년인데 무려 2017년까지 장장 10년 동안 소비자 제품군에서 접할 수 있는 코어 수는 최대 4개였던 것입니다. 하지만 AMD가 2017년에 개인용 CPU에서도 처음으로 최대 8코어 CPU를 발표하면서 코어 수 발전에 한 획을 긋게 되고 이후 2019년에는 16코어까지 늘리면서 코어 수 경쟁에 불을 붙이게 되었습니다. 그래서 2023년 기준으로는 인텔도 충분히 많은 코어수를 제공하며 경쟁을 하고 있습니다11.
 2023년 최신 인텔과 AMD CPU의 코어 수 (하이엔드 모델 기준)
2023년 최신 인텔과 AMD CPU의 코어 수 (하이엔드 모델 기준)
여담으로 CPU 스펙 표에 코어수 말고 스레드 수라고 하여 조금 다른 수치를 보이는 스펙이 있는데, 이 또한 멀티 코어 프로세서와 연관이 깊은 스펙입니다. 관련해서는 추후 운영체제 내용을 다룰 때 자세히 다루겠습니다.
3. 정리
여기까지 해서 ISA와 CPU의 실제 구현체라 할 수 있는 마이크로아키텍처의 개괄적인 내용을 알아보았습니다. 사실 2개 포스트로 CPU 포스트를 끝내고자 하였지만 분량 조절에 실패하여 언코어 파트를 전혀 다루지 않아 세 번째 편까지 작성할 예정입니다.
다음 편에는 CPU 본편의 마지막으로 메모리 컨트롤러, 캐시 메모리, 기타 주변 장치와의 연결을 담당하는 언코어 (Uncore) 파트를 알아보고 마무리하도록 하겠습니다. 긴 글 여기까지 읽어주셔서 정말 감사합니다.
코어 파트는 사실 아직 얘기할 내용이 많이 남아있습니다.
현대 CPU 코어의 핵심 기술인 파이프라인 (Pipeline), 비순차 실행 (Out-of-Order Execution), 슈퍼 스칼라 (Superscalar)등이 대표적인데
분량도 분량이고 내용도 좀 더 복잡하기에 나중에 기회가 되면 심화편 느낌으로 다루고자 합니다.
언제나 그렇지만 오류나 오해의 소지가 있는 내용이 있다면 언제든 알려주시면 감사하겠습니다.
최대한 정확한 설명을 지향하지만 설명을 간소화 하다 보니 이상한 부분이 분명 있을 것이라 생각합니다.
한가지 재밌는 점은 인텔과 AMD가 사용하는 ISA인 x64 (=AMD64)는 이름에서 알 수 있듯이 AMD가 라이센스를 가지고 있습니다. 그래서 인텔은 AMD로부터 이 ISA의 라이센스를 사서 CPU를 만들고 있습니다. ↩︎
각각 씨스크, 리스크로 발음합니다. ↩︎
https://chipsandcheese.com/2021/07/13/arm-or-x86-isa-doesnt-matter/ ↩︎
“거의” 같다고 표현한 이유는 최신 마이크로아키텍처는 일부 특수 명령어가 추가되기도 하기 때문입니다. 이 특수 명령어는 ISA의 기본 동작에는 영향을 미치지 않는 확장판 같은 것이라 보시면 됩니다. ↩︎
간단하다고 해도 딱히 짧지는 않을 예정이나, 진짜 각잡고 뜯어보면 전공 서적 분량도 나올 수 있습니다… ↩︎
아직 다루지 않았지만 정확히는 메모리 데이터의 일부를 저장하는 장치인 캐시 (Cache) 라는 CPU 내부의 고속 메모리에서 가져옵니다. 자세한 내용은 언코어 파트에서 다룹니다. ↩︎
언더바는 4비트 단위로 나눠서 보기 편하게 붙인 것입니다. 긴 숫자 표현할 때 천의 단위마다 붙이는 콤마 같은 것이라 보시면 됩니다. ↩︎
당연히 디코더 개수가 많다고 무조건 좋은 것은 아닙니다. 이유는 후술할 것이고, 원론적으로 공학은 언제나 trade-off 법칙이 작용함을 염두에 두는 게 좋습니다. ↩︎
부동 소수점은 대부분 IEEE-754라는 표준에 의해 정의됩니다. 관심 있으신 분은 한번 확인해보세요. ↩︎
이론과 현실은 언제나 다릅니다. 이론상은 그래도 현실적으로는 모든 상황에서 무조건 컴퓨터 속도가 2배 빨라지는 것은 아닙니다. ↩︎
다만 인텔은 2023년 기준으로는 다소 꼼수(?)로 코어수를 늘리고 있습니다. 주로 모바일 CPU에서 많이 채택하던 고성능 코어와 저성능 코어를 섞는 방식을 도입하여 고성능 코어는 6-8개 정도만 탑재하고 저성능 코어를 최소 4개에서 최대 16개까지 탑재하는 방식을 사용하여 코어수를 늘리고 있습니다. ↩︎